

Using Unicode in Visual FoxPro
Web and Desktop Applications
By Rick Strahl
www.west-wind.com
rstrahl@west-wind.com
Last Update:
December 14, 2008
What's covered:
Code for this article:
http://www.west-wind.com/presentations/foxunicode/foxunicode.zip
Unicode provides a universal display mechanism for strings in
an application. A common problem for applications is to display all the
different languages and character sets associated with them easily and
consistently. Unicode provides a single character set that can display all
languages with a single character representation mechanism that eases the
complexities of displaying very different languages such as Chinese, Korean,
Russian and Western Languages like English in a single form or Web page.
Unfortunately, Visual FoxPro doesn't have native Unicode support, which means
you have to do a bit of extra work and understand how to integrate strings from
multiple character sets and how to work with Unicode data in Visual FoxPro.
In this article, I describe how you can use Unicode with your
application in the context of supporting multiple languages simultaneously.
Although Visual FoxPro can’t display Unicode directly, it can display different
character set through use of CodePages – a locale specific character mapping -
which VFP readily supports. This works well for applications that display
content only from a single language/locale. But this approach has serious
limitations if you need to display strings from multiple languages
simultaneously. I start with an overview of the issues and how to work with
Unicode in general, then show you how to retrieve and update Unicode data, and
finally, show you how to get the Unicode content to display both in your Web and
desktop user interfaces.
Please note that most of the solutions
offered in this article rely on a couple of new Visual FoxPro 9.0 features,
so VFP 9 or later is highly recommended. The native VFP data access and Sql
Passthrough samples can work in VFP 8 or later.
Recently I was involved in a project where one of the
requirements was to create content that displays in a variety of languages
including Asian and Eastern European languages, using Unicode data stored in a
SQL Server database. My particular problem involved reading input from various
languages, saving the data to SQL Server and then displaying and capturing the
data from multiple languages on a single Web page.
Visual FoxPro doesn’t support Unicode directly so dealing
with extended character sets like Cyrillic or any of the Asian sets is rather
tough and somewhat confusing. It doesn’t help that there isn’t much
documentation on this subject. In this article I’ll describe my discoveries of
working with Unicode data in Visual FoxPro and how I eventually was able to
address this problem with several solutions. Although the focus in this
particular project was with Web data I’ll also briefly discuss Unicode inside of
the FoxPro user interface towards the end of the article.
What’s the problem?
Visual FoxPro uses ANSI characters, which is a non Unicode
character display mechanism. Instead it uses an n-byte (known confusingly as
multi-byte, but it means “1 or 2 bytes”) representation of characters.
Multi-byte character sets are based on code pages that represent a specific
character set mapped to one or more languages. For example, CodePage 1252 –
Windows Western – maps to most English and Western European languages. 1251 maps
to Eastern European languages like Polish. and so on. This pre-Unicode mechanism
was common in the days of DOS and Win16 and is still in use for non-Unicode
applications running on 32 bit Windows today. The problem with this mechanism is
that this scheme of code pages makes it very difficult to display content of
multiple code pages at the same time. So if you want to display Russian and
Chinese text on the same page it is impossible to do because you can only use
one code page at a time.
When Win32 came around, Microsoft pushed hard for a full
Unicode implementation and Windows 95 and later are based primarily on Unicode
characters. At the time this caused quite a stir because most development tools
of the day did not support Unicode yet. Unicode at Microsoft really didn’t come
into full fruition until Visual Basic and COM came into being in the early
1990’s. Microsoft’s COM component interface was entirely based on a Unicode
based string system that was totally transparent to the developer.
Visual FoxPro, however, stayed with internal multi-byte
character presentations and, to this day, has only minimal support for Unicode.
The extent of its Unicode functionality is basically a few functions that allow
you to convert strings (in a fairly limited manner) between multi-byte and
Unicode, as well as a few string functions that can operate on Unicode strings.
However, VFP has no way to actually display Unicode strings using its native
controls.
Visual FoxPro can, however, consume Unicode data to some
extent by performing automatic code page translations. By default Visual FoxPro
uses a code page that matches the system settings. Every time any sort of
conversion needs to take place – when reading Unicode data from a data source
like SQL Server or accessing a COM object – Visual FoxPro automatically converts
the string from Unicode into the appropriate code page, and vice-versa.. This
works fine as long as the data you’re working with maps uniquely into this
particular code page. So if I work with English/Western data all day long I
will never have a problem with Unicode data. That is until you start dealing
with extended character sets that don’t match your current system’s code page.
You have some control over this process by setting VFP’s code page, and using
SYS(3101) - new in VFP 9 - which lets you configure how Visual FoxPro translates strings from COM
objects. You can also convert strings directly to and from Unicode by using STRCONV() with nConversionSetting options 5 and 6 respectively. These functions
allow you take a FoxPro string and convert it into Unicode and back using an
optional code page (or locale identifier) parameter to specify how the
translation occurs.
All this means that if you are running Windows in a Korean code page and you
retrieve Korean data from the database VFP can deal with this data just fine
both in string format and in the user interface. However, if you are running in
the English version of Windows and are trying to read that same Korean data you
will find that VFP cannot read or display this data (you get a bunch of question
marks). While VFP can be coerced to convert strings using specific code pages
(with STRCONV() or SYS(3101) for example) the FoxPro UI can only deal with a
single code page at time.
You can add a secondary ‘multi-byte’ conversion language to
your system in the Control Panel | Regional Settings | Advanced as shown in
Figure 1. Unfortunately this setting is a pain to set – you have to reboot after
changing it.
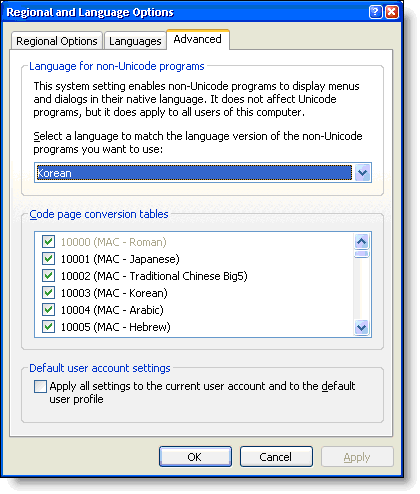
Figure 1: Configuring your default Unicode to
Multi-byte translation language. The language you choose here will be VFP’s
default extended character set used to display text.
With the settings made I would be able to do conversions
for Korean and I would be able to use and display strings in Korean format in my
VFP applications. But I still wouldn’t be able to do the same for Chinese or
Russian at the same time. In other words, the above option only works for a
single language, which might be fine for an application that has to work only
with a single language at a time.
Doing conversions this way is also very limited as your
application has to be very aware which code page you are converting to and from
in Visual FoxPro – without this information Unicode conversions from upper
character sets that are very different from the machine default code page will
result in lost or modified characters – a loss of data.
It’s very likely that if you convert Unicode characters
from a non-default code page, you will not be able to convert these strings to a
useful Visual FoxPro string in the VFP environment. If your machine is
configured for code page 1252, and you read a Korean Unicode string and convert
it to a FoxPro string with STRCONV() you will find that you get a string full of
???. The ? character indicates that VFP didn’t know how to convert this
character into something that can be represented in the current code page. And
this is really the crux of the problem with VFP’s Unicode support.
You can apply a CodePage or Locale to the conversion in
which case Visual FoxPro will actually generate the right locale specific
character sequence for you. Try out the following:
*** Korean Text as binary
Unicode
lcBinStr=STRCONV("IAAgACAAIADIwG24jKwgAIzBHKwY"
+ ;
"tJSyIABLusTJIADostC5MK4gAHzOfLcgAA==",14)
*** Convert to UTF-8
lcUTF8Str =
STRCONV(lcBinStr,10)
? lcUTF8Str
*** Plain STRCONV() - gives
???
lcRawFoxString =
STRCONV(lcUTF8Str,11)
? lcFoxString
*** Convert UTF-8 to Korean
DBCS text
*** Creates ‘gibberish’
text in English, but OK in Korean
lcFoxString =
STRCONV(lcUTF8Str,11,1042)
?
lcFoxString
Although the latter approach would work to create a string
in VFP that can display in a Korean system, it will be just another encoded
format for your English version. The latter also requires that you know
beforehand what locale you’re dealing with which is difficult if you work with
multiple languages – which requires storing the locale with string somehow
(database field etc.).
If you need to deal with strings that come from multiple
character sets at a the same time (for example an application that uses English,
Russian, Chinese and Korean all at the same time) the only way to work with this
string data is by not converting it into the current code page, but rather use a
neutral representation of the string instead. There are two ways that I’ve used
for this: binary or UTF-8. Binary is a raw binary representation of the Unicode
characters. UTF-8 is an encoded Unicode format that can be represented in two
bytes. UTF-8 works by using multiple character combinations for upper Unicode
characters that can take as much as 4 characters. You can pass Unicode data
around the system in one of these formats without losing the formatting of the
string. This maintains the string’s integrity, but it also means that the string
can likely not be used as you would normally use it, since it is not the actual
string but a representation of the string. Anytime you need to work with
the string you’ll have to convert the string. For example comparing two strings
might require you to convert both strings into a common format that VFP can work
with. Doing a STRTRAN() replacement on a UTF-8 encoded string might not get you
the results you expect, for example.
Another big problem is that you can’t display these strings
in FoxPro user interface controls, because the native Fox controls only work
with current character set encodings. I’ll show you a workaround for this
towards the end by using ActiveX controls and SYS(3101,65001) to force VFP to
pass strings in convert strings to UTF-8 format to be passed to the ActiveX
control. VFP performs the UTF-8 to Unicode and back conversions for us.
If you are working with Web applications, the display issue
is a bit easier than with Windows Forms because web browsers are natively
Unicode and UTF-8 enabled. Most web pages you see online are UTF-8 encoded and
if you generate output in UTF-8 format you can easily display multiple language
representations on a single page. UTF-8 is easy to generate and decode from in
Visual FoxPro using STRCONV. You can convert to and from UTF-8 both from VFP’s
native multi-byte characters as well as to and from Unicode.
Essential Conversions
Enough theory. Let’s look at some examples.
Before we can look at data access it’s important to
understand how VFP can convert strings between Unicode and multi-byte. It’s also
helpful to understand how you can deal with Unicode data coming from COM in VFP.
The key mechanism for converting strings is the STRCONV()
function. To convert a string from VFP multi-byte to Unicode you can simply do:
lcUnicode =
STRCONV("Hello
World",5)
_cliptext = lcUnicode
? lcUnicode
The following converts a plain ANSI string to Unicode. The
output of this conversion is:
H e l
l o W o r l d
Unicode is a double byte character set so every character
is presented by at least two bytes. The spaces between the words aren’t actually
spaces but CHR(0)s.
To go the other way we can now use 6 as the parameter:
lcAnsi =
STRCONV(lcUnicode,6)
?
lcAnsi
And voila we have our Hello World string back.
The example above works because we’re working within the
default locale of the machine. The call to STRCONV() used the default locale,
which in my case would be code page 1252 (ANSI – Western Windows). If I tried
the above conversion with a string that contained Chinese characters the
conversion would fail.
Worse, VFP can’t represent an extended string in the UI.
For example, if I pick up some Chinese text from a Web page and paste it into
VFP I only get a bunch of question marks like this:
??????
To help working with other locales than the currently
installed one, you can pass a Locale Id (such as 1033 for US English) or a
codepage (like 1252 for Western Windows) in the third parameter of STRCONV(). Be
careful with these values though, and understand that they will produce locale
encoded strings that won’t display properly in VFP unless you are running in
that specific locale. If you take a Chinese string and convert it to DBCS with
the Chinese code page, the string won’t contain ??? but it will contain
something human unreadable and certainly not Chinese looking in your English
version of VFP. So still no Chinese for you. At the same time realize though that the
data is, in fact, a Chinese double byte representation of your text.
While this may suffice for applications work in a single
locale (ie. an application always running in Chinese), this is a problem for
applications that may display data from multiple locales. In that scenario you’d
have to keep track of the locale information for each record, which becomes a
mess quickly. For this reason, it’s much better to bypass this situation
altogether and deal with Unicode inside of VFP as binary or UTF-8 data because
it is essentially a universal format that works for all locales.
So how can we get Chinese data into our application? You
need to represent the data as binary. So if you read Unicode data from a
database in binary format you can assign it as a binary value to a VFP variable.
You can also do this manually with a base64 or HexDecimal representations. For
example:
lcUnicode =
STRCONV("rpt3gmlfcoJnUW5/b5g6eU9c",14)
This assigns a Chinese Unicode string to the lcUnicode
variable. If you were working with Chinese data all around you’ll be best served
to pass the data through your application as binary data rather than trying to
convert it into specific code page as you are bound to loose the string in the
VFP code page conversions.
If you think this is messy, you’re right.
COM Objects
COM objects always accept and represent strings in Unicode
format. So every time VFP calls a COM object a conversion happens behind the
scenes converting VFP strings to and from Unicode. By default it uses the
current locale settings for the conversion, so if data from an extended locale
comes back VFP will have problems presenting that locale’s data in a VFP string.
To work around this issue Visual FoxPro 9.0 introduces a
new SYS(3101) function that tells VFP to return the
COM data to you in UTF-8 format (or any specific locale you specify):
SYS(3101,65001)
This tells VFP to convert all data to and from UTF-8. If
you are retrieving extended character strings it makes sense to pull the data
out in UTF-8 format and then perform any additional conversions to Unicode when
you need to store the data to the database. As you’ll see a little later this
option is very useful when dealing with data passed through ADO, because ADO is
an all-COM interface to the data.
Working with Unicode Data in Visual FoxPro
If you need to work with Unicode data in Visual FoxPro, you
want to treat the Unicode data inside of Visual FoxPro as binary or UTF-8. The
following examples all rely on Visual FoxPro 9 because it makes the type casting
a lot easier – you can do most tasks with VFP 8 as well, but it’s a little more
verbose and less consistent. The VFP 9 CAST() function is very useful for
consistent type conversions.
Visual FoxPro doesn’t have any native Unicode field types.
Unlike SQL Server or most other SQL data bases Visual FoxPro can’t represent
Unicode data internally unless you use a binary format to store it.
Using binary data is not optimal because you loose the
ability to treat the data like a string. String comparisons are not easy, the
data cannot sort according to language sorting patterns and anytime you do
anything with the data it requires that you convert. But you can at least store
this data. The following code snippet demonstrates how create a table and get
some Unicode binary data into it:
IF
!FILE("wwdemo\ForeignData.dbf")
*** Create table with
binary text fields!
CREATE TABLE
wwdemo\FOREIGNDATA ;
(
ID
C(10),;
DESCRIPT
Blob,;
LDESCRIPT
Blob);
USE
ForeignData
Shared
*** Load up sample data as
binary Unicode!
INSERT INTO
ForeignData ;
(
id,descript,lDescript)
VALUES;
(
SYS(2015),
STRCONV("Korean",5),;
STRCONV("IAAgACAAIADIwG24jKwgAIzBHKwYtJSyIABLusTJIADostC5MK4gAHzOfLcgAA==",14))
INSERT INTO
ForeignData ;
(
id,descript,lDescript)
VALUES;
(
SYS(2015),STRCONV(
"Chinese",5) ,;
STRCONV("rpt3gmlfcoJnUW5/b5g6eU9c",14)
)
INSERT INTO
ForeignData ;
(
id,descript,lDescript)
VALUES;
(
SYS(2015),STRCONV(
"Russian",5),;
STRCONV("EQQ+BDsETARIBD4EOQQgAEYEMgQ1BEIEPQQ+BDkEIAAyBD0EQwRCBEAENQQ9BD0EOAQ5BCAANAQ4BEEEPwQ7BDUEOQQ=",14)
)
ELSE
USE
ForeignData
IN
0
ENDIF
SELECT
ForeignData
As you can see the strings are being loaded using Base64
encoded text rather than the actual string. That’s because VFP can’t represent
the string directly, so to get these strings I ran a query that returned binary
data and encoded it into Base64. You can also use HexBinary encoding ( STRCONV(,15)
) in the same way. Obviously if you’re capturing this data in your UI a
different approach will be needed. We’ll get to that shortly. The above loads up
the data in binary format – but remember that this data is merely a binary
Unicode string representation.
If you were to look at the Descript field in the table
you’d see double spaced characters. The binary data for the exotic languages on
the other hand will look like binary garbage. You will not see a character
representation because VFP cannot deal with these extended Unicode characters.
But the data is actually there as Unicode. Note that you don’t get ???? in the
field, because the data is binary.
Next let’s retrieve this data and use it. To so we’ll query
and convert the data to UTF-8. We can simply retrieve this data with:
select Id,Descript
as
Note,LDescript
as
Description ;
FROM
ForeignData
INTO CURSOR
TFData
This returns the data as binary. To convert it to UTF-8 we
can re-query and use STRCONV():
SELECT Id,;
CAST(STRCONV(Note,10)
as
M)
as
Note ,;
CAST(STRCONV(Description,10)
as
M)
as
Description;
FROM
TFData ;
INTO
CURSOR TFData2
You can do this in a single SQL statement, but I separate
it out here for clarity. Once we have the UTF-8 data, it’s ready to be embedded
into an HTML document. We can display our multi-cultural data now by creating
an HTML string:
TEXT TO
lcHTML
<HTML>
<HEAD>
<meta
http-equiv="Content-Type" content="text/html; charset=utf-8">
</HEAD>
<body>
<h1>VFP
Unicode Data
Representation</h1>
<hr>
ENDTEXT
*** UTF-8 Encode - not
necessary here, but if you had extended text
*** you'd need to do this
lcHtml =
STRCONV(lcHTML,9)
SCAN
lcHTML = lcHTML + Note + "
- " + Description + ;
"<hr>" +
CHR(13)
+ CHR(10)
ENDSCAN
lcHTML = lcHTML +
"</body></html>"
ShowHtml(lcHtml)
The key is the character encoding in the Meta tag that lets
the browser know that this data will be UTF-8 encoded and should display as
Unicode. The result is shown in Figure 2.
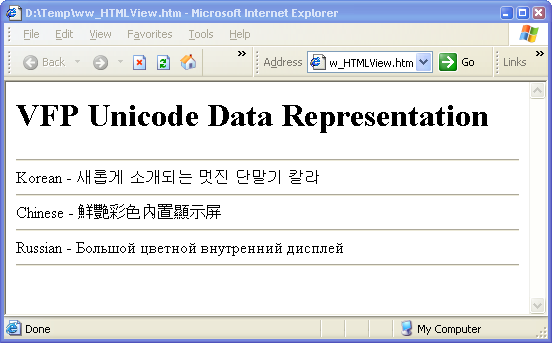
Figure 2: Displaying the multi-cultural Unicode
data retrieved from the FoxPro database’s binary fields.
Next we’ll need to write data captured from a Web page to
the table and we need to do pretty much the same thing in reverse. I’ll use a
Web form as an example, in this case using an all VFP solution with Web
Connection. I’ll then look at using code from within an ASP COM component.
Writing out and Capturing data with Web Connection
If you’re using an all VFP solution any form data captured
on an HTML form will come back formatted based on the CharSet of the HTML
document. If we were generating the data like above for a Web page display you’d
explicitly set the character set as part of the content type. This means you
need to make sure that you generate your output and properly encode it.
This sounds simple, but it can be a bit involved if you’re
using VFP data because you may have to encode the template code as well as the
data. For the example shown in Figure 3 below the data is merged into a
template, while the actual data for the table is generated off a cursor.
***
The SQL statement to retrieve the data - UTF-8 encoded
SELECT Id,;
PADR(STRCONV(Note,10)
as
Note, ;
PADR(STRCONV(Description,10)
as
Description ;
FROM
TFData ;
INTO
CURSOR TFData2
*** Create Grid from Data –
remember data is already UTF8 encoded!
loSC =
CREATEOBJECT("wwShowCursor")
loSC.ShowCursor()
pcCursorText =
loSC.GetOutput()
*** Load the template and
UTF-8 Encode
lcTemplate =
STRCONV(
FileToStr( Request.GetPhysicalPath() ),9)
*** Merge template with our
content – pcCursorText is already UTF-8 encoded
*** and gets embedded into
the template
lcEncodedResult = MergeText(@lcTemplate)
*** Create HTTP header to
include the proper Content Type and charset
Response.ContentType =
"text/html; charset=utf-8"
*** Write it all out to the
Web Server
Response.Write(
loHeader.Getoutput() )
Response.Write(lcEncodedResult)
The result then is a fully UTF-8 encoded document as shown
in Figure 3. Note that the Content-Type is returned explicitly as text/html with
a charset of UTF-8! This is important, so the browser knows to display this page
as Unicode (without character encoding) rather than the default configured
character set. Without this the browser would try and guess the code page and in
the case of UTF-8 the guess is usually wrong. It’s very important to set the
Content-Type correctly!
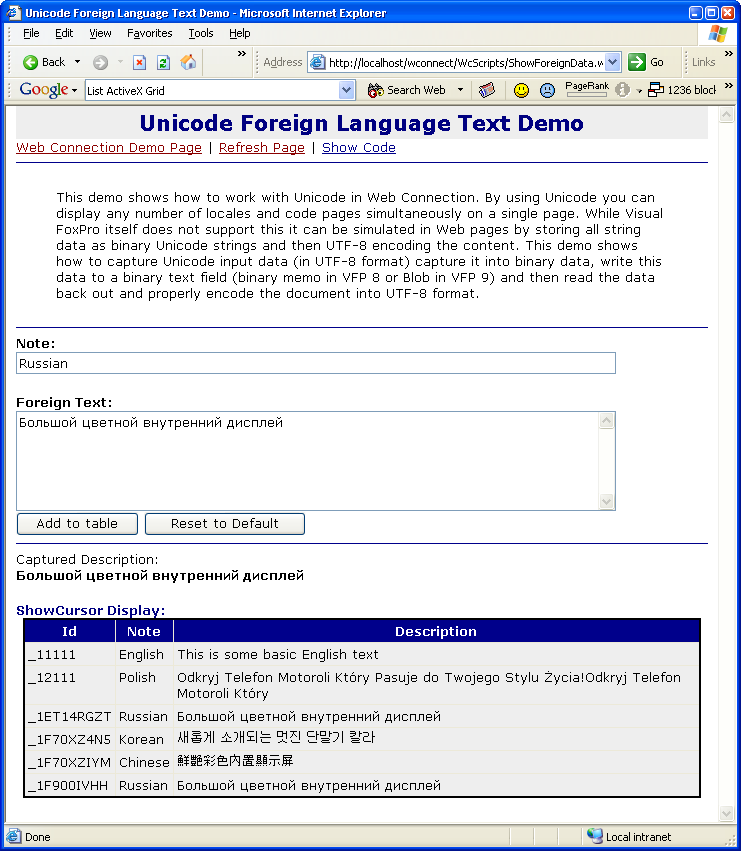
Figure 3: Capturing data on a Web Form happens
using the Web Page’s character encoding – in this case UTF-8. User Input is
captured as Unicode in UTF-8 format and then converted and written to the
database as binary.
This form also allows capturing of data in any language and
it adds to the form. We can now capture the data from the input field like this:
IF
Request.IsPostBack()
*** Read the raw input data
– format is UTF-8 because page is UTF-8 encoded
pcSavedDescription =
Request.Form("txtDescription")
*** Convert UTF-8 to
Unicode and store as BINARY string!!!
pcSavedDescription =
STRCONV(pcSavedDescription,12)
*** One more time for the
title string
pcSavedTitle = Request.Form("txtTitle")
pcSavedTitle =
STRCONV(pcSavedTitle,12)
*** Now insert the BINARY
string into the text as nVarChar
insert into
ForeignData(id,descript,lDescript)
values
;
(SYS(2015),pcSavedTitle,pcSavedDescription
)
select Id,Descript
as
Note,LDescript
as
Description
FROM
ForeignData
INTO CURSOR TFData
ENDIF
Notice that the data from Request.Form() is UTF-8 encoded
because the Web page’s character set is UTF-8. Any Form data posted back comes
back in UTF-8 format. We now have to convert this UTF-8 into a Unicode string.
Remember that the Descript and lDescript fields are binary fields and we’re
taking the Unicode data and storing it as is into those binary fields.
You can view this entire demo online including source code
at:
http://www.west-wind.com/wconnect/WcScripts/ShowForeignData.wwd
Capturing Data with a VFP COM component in ASP or ASP.NET
If you’re using ASP or ASP.NET with a Visual FoxPro COM
component the behavior will be slightly different. In these environments, ASP
and ASP.NET objects are COM objects that already understand Unicode. VFP still
doesn’t, but you can pass data to and from these objects with UTF-8 using
SYS(3101).
The key difference is how we can pass data to the COM
object. In the Web Connection example I explicitly converted everything to
UTF-8. If you have extended character sets you still have to do this inside of a
VFP COM object. You’ll use the
SYS(3101,65001)
function to pass any data to ASP.NET in UTF-8 format. Using this function
basically does two things:
- It tells the COM object that data is sent in UTF-8
format – you’re responsible for encoding to UTF-8 and VFP does the rest.
- It tells the COM object to return the data to you in
UTF-8 format and you will be responsible for decoding it.
The easiest thing is to simply call
SYS(3101,65001)
at the being of your ASP/COM method (or in the Init of the component) and
always pass and read data by UTF-8 conversion.
The process involved is to capture the ASP context object
and retrieve the various worker objects off it. You can do this with the
following code within any method of a COM component called from ASP or ASP.NET
(with ASPCOMPAT set to true):
SYS(3101,65001)
&& Return Unicode data in UTF-8 format
oMTS =
CreateObject("MTxAS.AppServer.1")
THIS.oScriptingContext
= oMTS.GetObjectContext()
loRequest = oContext.item("Request")
At this point you can then retrieve data from the
ASP/ASP.NET Request object.
IF !ISNULL(
Request.Form("txtDescription").Item() )
*** Read the raw input data
– Data will be UTF-8
pcSavedDescription =
Request.Form("txtDescription").Item()
*** Convert UTF-8 to
Unicode and store as BINARY string!!!
pcSavedDescription =
STRCONV(pcSavedDescription,12)
pcSavedTitle = Request.Form("txtTitle").Item()
pcSavedTitle =
STRCONV(pcSavedTitle,12)
*** Now insert the BINARY
string into the text as nVarChar
insert into
ForeignData(id,descript,lDescript)
values
;
(SYS(2015),pcSavedTitle,pcSavedDescription
)
select Id,Descript
as
Note,LDescript
as
Description
FROM
ForeignData
INTO CURSOR TFData
ENDIF
The same is true if you’re writing output to Response.Write()
or back to the Page or one of the controls on it. The following converts from
Unicode to UTF-8 for display:
Response.Write(
STRCONV( lcUniCodeString, 10) )
Remember that ASP and ASP.Net pages by default are UTF-8
encoded so you want write any raw output in this format. Make sure however, that
the default has not been overridden at the ASP page level.
When working with VFP data you can choose to store the data
in the database either as binary Unicode as I showed here or as UTF-8. If you
are building a pure Web application it might actually make sense to use UTF-8
as data passes through the system in UTF-8 – it might save a few conversions.
The main reason I used binary data here is because it matches with the Unicode
retrieval through ODBC as we’ll see next.
Ok, so now you’ve seen the full cycle of displaying and
retrieving Unicode data with FoxPro data. Essentially you need to work with data
in a non-standard way. If you use VFP data tables to hold Unicode data you will
need to work with binary or UTF-8 data, which means you loose the ability to
effectively index or search the data which can become very inefficient. Since
the VFP data engine has no knowledge of Unicode as a data type it can only index
your data in binary. This may or not be sufficient.
A better choice is to use a Unicode enabled back end like
SQL Server. With SQL Server you actually have two choices for working with
Unicode: SQL pass through, which uses ODBC, or ADO, which uses COM and OleDb.
Let’s look at those two approaches…
Doing Unicode with Sql Server and SQL Pass Through
Sql Server supports native Unicode data types in the nChar,
nVarChar and nText types. These types allow storage of true Unicode strings that
are fully searchable and can be properly indexed. Indexing of Unicode fields is
actually a tricky matter as well because Unicode can potentially represent
multiple locales and so for Unicode fields in SQL Server 2000 you can choose an
indexing collation that is used to determine index order.
SQL pass through (SPT) is FoxPro’s oldest and in most cases
most efficient access mechanism to access SQL data sources including SQL Server.
SPT is effectively VFP’s only native data access mechanism to SQL Server upon
which other technologies like remote views and the CursorAdapter base class are
built.
Because VFP doesn’t provide a native Unicode type, SPT is
also somewhat limited in what you can do with Unicode data retrieved from SQL
Server. The problem is that while you can query data from SQL Server in Unicode
fields, ODBC will try to convert that data into the default code page running on
the machine. For example if I run the following code:
lnHandle =SQLStringCONNECT(;
"driver={sql
Server};server=(local);"+;
"database=WestWindAdmin")
?
SQLEXEC(lnHandle,"select
Id,descript as Note," + ;
"CAST(lDescript
as nVarChar(120)) as Description"+;
"from foreignData")
BROWSE
it retrieves the data that is displayed in Web page from
Figure 2. The unacceptable Browse result is shown in Figure 4.
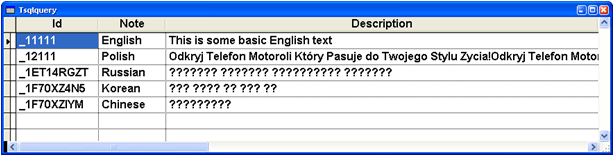
Figure 4: Unicode data returned from SQL Server
may not be quite what you expect. The raw data will convert to the default code
page for the system and any conversion can only do a single code page at a time.
This is not quite what we’re looking for. The data is
returned with an auto-conversion to the current code page that the system is
running in. This means I can see the English text just fine and even some of the
Polish characters (those that match the 1252 character set) look OK. But if you
look closely even at the Polish text you’ll see that the translation is not
working and that some characters are missing their accents. For the Russian,
Korean and Chinese ODBC couldn’t convert at all so the entire strings are
returned as ??? characters.
So retrieving the data as string values into VFP is not
possible from SQL Server any more than it was with VFP earlier. But as with the
VFP data we can also return the data as binary:
SqlExec(lnHandle,[select
ID,] +;
[CAST(CAST(Descript as
nVarChar(4000)) as VarBinary(8000)) as Note,] +;
[CAST(CAST(lDescript as
nVarChar(4000)) as VarBinary(8000)) as Description] +;
[from ForeignData],"TFData")
When you run this SQL Statement you’ll get back a cursor
with two binary memo fields and these memo fields will contain binary Unicode
strings. Note that this basically converts the nVarChar and nText data into
VarBinary which is the only way to return this data to VFP without encoding.
Unfortunately there’s no direct conversion from nText to binary, so we have to
go the intermediate route of using nVarChar. Because nVarChar is limited to a
max size of 4000 characters the conversion is limited: A major limitation if you
have large data fields.
As with the VFP code, the binary data is not all that
useful so we need to convert to UTF-8 first by re-filtering the data into UTF-8:
SELECT Id,;
CAST(STRCONV(Note,10)
as
M)
as
Note , ;
CAST(STRCONV(Description,10)
as
M)
as
Description ;
FROM
TFData ;
INTO CURSOR
TFData2
At this point we can use the data the same way as we did in
the Web page example earlier by simply embedding the UTF-8 text into the Web
page.
To write the data back we need to take our UTF-8 input,
convert it to binary and then cast it in SQL Server back to nVarChar. Note, that
you can’t cast to nText – SQL Server doesn’t allow casting to nText or Image
data. The abbreviated process looks like this:
*** UTF-8 to Unicode
conversion
pcSavedDescription =
STRCONV(pcSavedDescription,12)
pcSavedTitle =
STRCONV(pcSavedTitle,12)
*** Must explicitly force
to binary – can also use CAST in 9.0
pcSavedTitle =
CREATEBINARY(pcSavedTitle)
pcSavedDescription =
CREATEBINARY(pcSavedDescription)
*** SQL Server requires
CASTS on the server!
SqlExec([insert
into ForeignData (ID,Descript,lDescript) values ] +;
[(?pcID,
CAST(?pcSavedTitle as nVarChar(4000)),] +;
[CAST(?pcSavedDescription
as nVarChar(4000) ) ) ] )
This is a fairly complicated mechanism as you really have
to understand the underlying mechanics of this process to make this work. You
also have to embed CASTS into every SQL statement which is a real mess for any
business logic. But most importantly understand that you are limited to 4000
characters of Unicode text with this approach because of the nVarChar limit of
4000 Unicode characters, which makes this a partial solution at best. However,
it can be useful if you only need Unicode functionality in one or two places in
your existing application that already uses SQL pass through.
SQL pass through would be workable if VFP had a Unicode
aware database type that could at least retrieve and write Unicode data without
any sort of conversion to binary (or UTF-8) from which we could convert. This
would allow reading and writing nText data to the server directly and overcome
this string limit. Maybe next version…
Retrieving Unicode with ADO
To work around this shortcoming in SQL pass through, you
have to work with ADO. ADO is COM-based and allows direct access to Unicode
data. As mentioned earlier COM inherently uses Unicode for all strings and by
using SYS(3101) we can gain more control over the Unicode strings returned from
SQL Server (or other backend).
Visual FoxPro 9.0 required for
this solution
SYS(3101) and the
CursorAdapter’s ADOCodePage property are new in Visual FoxPro 9.0. Since
these two features are vital to making ADO properly translate Unicode data you
need to use Visual FoxPro 9.0 for this solution to work.
In addition, we can also use the CursorAdapter class in VFP
9 or later. The CursorAdapter can work directly against ADO, and it sports a
code page property that allows you to return data in a specific code page
including the 65001 code page which is UTF-8.
Let’s look at a couple of examples on how to retrieve and
update data via ADO. The first example retrieves data using plain ADO and
returning an ADO Recordset object:
FUNCTION
AdoRecordSetQuery()
*** Make COM use UTF-8 code
page for strings
SYS(3101,65001)
LOCAL
oConn
as
ADODB.Connection
oConn =
CREATEOBJECT("ADODB.Connection")
oConn.ConnectionString =
this.cADOConnectionString
oConn.Open()
LOCAL
oCommand
as
ADODB.Command
oCommand =
CREATEOBJECT("ADODB.Command")
oCommand.ActiveConnection =
oConn
oCommand.CommandText = ;
"Select Descript,
lDescript as Description " + ;
"from foreigndata"
LOCAL
oRS
as
ADODB.RecordSet
oRS = oCommand.Execute()
lcHTML =
this.HtmlHeader("ADO
Recordset via COM")
***
IF
!ISNULL(oRS)
AND oRS.State = 1
DO while
!oRS.EOF
lcHtml = lcHTML + ;
oRS.Fields("Descript").Value
+ " - " +;
oRS.Fields("Description").Value
+ "<hr>" +
CHR(13)
+ CHR(10)
oRS.MoveNext()
ENDDO
ELSE
WAIT WINDOW
"SQL command failed."
NOWAIT
RETURN
ENDIF
lcHTML = lcHtml +
"</body></html>"
ShowHtml(lcHTML)
The data is returned as an ADO RecordSet here. The data
resides in a COM collection and we can return the results in UTF-8 format easily
by way of SYS(3101,65001), which instructs VFP to pass strings to COM as
UTF-8.
Notice that the SQL statement is passed as a plain string.
In theory every string passed to the COM object now needs to be UTF-8 encoded,
but since UTF-8 maps to the lower ASCII set, for plain command strings no
encoding is required; if you embed string literals however you should encode
your command strings. Also note that the SQL command is a straight SQL command
against the Unicode data. Unlike SPT, there are no CASTs or other conversions
but we simply execute the SQL statement as needed.
Because the result is a RecordSet we can’t use the data as
a cursor. However we can loop through the RecordSet and pull out any values.
Each of those values is UTF-8 encoded and ready to be embedded into a web page.
The code loops and builds an HTML document that displays data in the same format
as Figure 1.
Cool – we can now retrieve our data – but we still don’t
have a cursor. To convert a RecordSet into a FoxPro Cursor we can use the
CursorAdapter object in Visual FoxPro. Here is the same routine as above using
the CursorAdapter:
FUNCTION
AdoQuery()
pcLang="%"
&& Our query parameter
LOCAL
oConn
as
ADODB.Connection
oConn =
CREATEOBJECT("ADODB.Connection")
oConn.Open(this.cADOConnectionString)
LOCAL
oCommand
as
ADODB.Command
oCommand =
CREATEOBJECT("ADODB.Command")
oCommand.ActiveConnection =
oConn
LOCAL
oRS
as
ADODB.RecordSet
oRS =
CREATEOBJECT("ADODB.RecordSet")
oRS.ActiveConnection =
oConn
LOCAL
oCA
as CursorAdapter
oCA =
CREATEOBJECT("CursorAdapter")
oCA.ADOcode
page = 65001
oCA.Alias
= "TSqlQUery"
oCA.DataSourceType
= "ADO"
oCA.DataSource
= oRS
oCA.SelectCmd
= ;
"Select Descript,
lDescript as Description " + ;
"from foreigndata where
descript like ?pcLang"
*** Force all data at once
into cursor
oCA.FetchSize = 99999999
IF USED(oCA.Alias)
USE IN
(oCA.Alias)
ENDIF
*** Fill the cursor based
on Command object
*** Must pass Command
object to get parameter parsing to work
IF
!oCA.CursorFill(,,,oCommand)
AERROR(laErrors)
? lAERRORS[1]
? lAERRORs[2]
RETURN
ENDIF
*** Make free standing
cursor
oCA.CursorDetach()
BROWSE
When using the CursorAdapter you split your work between
the CA and the ADO COM objects. Notice that the CursorAdapter’s code page
property is set to 65001, which ensures that VFP communicates with ADO using
UTF-8 for strings.
The SQL command is set on the CursorAdapter rather than the
ADO Command object and the CA handles the command parsing. This makes it
possible to use SQL pass through type syntax with ADO, as the CA handles the
translation from SPT parameter syntax to the appropriate ADO parameter objects.
If you like the CursorAdapter, it can provide you with full
round trip support of the data. When configured with
INSERT/UPDATE/DELETE/SELECT commands the CA can manage the full range of remote
connectivity for updating a cursor and since it uses ADO and COM all your
Unicode management is taken care of for you.
If you’re like me though, you may find that the
CursorAdapter doesn’t fit with your existing business object architecture. I
rather deal with SQL more directly, rather than working with the preconfigured
remote view type interface that the CursorAdapter provides. To do this I need to
fire non-query commands (INSERT/UPDATE/DELETE/Stored Procedures) directly
against ADO.
Here’s an example of how to do this. The following shows
the raw syntax to perform an INSERT to ADO with Unicode data that is UTF-8
encoded:
FUNCTION
AdoInsert()
*** Some Russian text -
must convert to UTF-8 for Insert
lDescriptBin =
STRCONV(;
"EQQ+BDsETARIBD4EOQQgAEYEMgQ1BEIEPQQ+BDkEIAAyBD0EQ"+;
"wRCBEAENQQ9BD0EOAQ5BCAANAQ4BEEEPwQ7BDUEOQQ=",14)
lcDescriptUtf8 =
STRCONV(lDescriptBin,10)
pcID =
SYS(2015)
pcDescript = "Russian"
pclDescript =
lcDescriptUtf8
lcSql = [Insert into
ForeignData ]
[(id,descript,lDescript)
values ] +;
[(?pcId,?ocDescript,?pclDescript)]
SYS(3101,65001)
LOCAL
oConn
as
ADODB.Connection
oConn =
CREATEOBJECT("ADODB.Connection")
oConn.ConnectionString =
THIS.cAdoConnectionString
oConn.Open()
LOCAL
oCommand
as
ADODB.Command
oCommand =
CREATEOBJECT("ADODB.Command")
oCommand.ActiveConnection =
oConn
oCommand.CommandText =
lcSQL
LOCAL
oParameter
as
ADODB.Parameter
oParameter =
CREATEOBJECT("ADODB.Parameter")
oParameter.Type=
202 && adVarWChar
oParameter.Value
= pcId
oParameter.Size
=
LEN(pcID)
oCommand.Parameters.Append(oParameter)
*** Or wrappered
this.AdoAddParameter(oCommand,pcDescript)
this.AdoAddParameter(oCommand,pclDescript)
lnAffected = 0
? oCommand.Execute(@lnAffected,,128)
&& No result set
The process should be familiar to you by now. Any string
you want to pass to SQL Server should be UTF-8 encoded. The Russian text above
starts in binary (because I can’t paste it into the text), is converted to UTF-8
and then assigned to a parameter object’s Value property in ADO. ADO is set to
SYS(3101,65001) so all parameters are passed in as UTF-8 and internally
converted to Unicode. If you watch SQL Profiler you will see that ADO indeed
sends strings in Unicode format to the server when the INSERT runs.
The same logic applies for UPDATE commands or stored
procedure calls that require parameters to be passed. Note that with native ADO
you will have to explicitly assign parameters using the ADODB.Parameter object
rather than the familiar SQL pass through syntax. To make parameter passing a
little easier the sample code that comes with this article provides a
AdoAddParameter() method that lets you pass just the essentials (value and
name).
Making life easier with SQL Server Class Wrappers
To make plain SQL syntax more consistent, I’ve provided a
couple of classes – wwSQL and wwADOSQL – that provide a low level SQL
implementation that works with both ODBC and ADO transparently. The wwSQL class
was originally built as a very thin wrapper around SQL pass through and I
recently added wwADOSql with the same interface to support Unicode
functionality. The core methods of this class are Execute(), ExecuteNonQuery()
and ExecuteStoredProcedure() plus a common parameter implementation that is not
dependent on private variables (ie. you can pass it around in distributed
applications). The class also manages parameter parsing from SQL pass through
syntax for all but Stored Procedure calls with OUT parameters, which must be
explicitly implemented using ExecuteStoredProcedure(). This class is quite
useful if you are more comfortable with a SQL pass through style direct SQL
interface.
With this class SQL access and working with ADO UTF-8
strings becomes as simple as:
LOCAL
o
as
wwADOSql
IF
.T.
o =
CREATEOBJECT("wwADOSql")
o.ncode page=65001
? o.Connect("Provider=sqloledb;Data
Source=(local);"+;
"Initial
Catalog=WestwindAdmin;"+;
"Integrated
Security=SSPI")
ELSE
o =
CREATEOBJECT("wwSql")
? o.Connect("driver={sql
server};server=(local);database=WestWindAdmin")
ENDIF
? o.Execute("select * from
foreigndata") && Utf-8 data returned
if o.lError
? o.cErrorMsg
RETURN
endif
BROWSE
o.AddParameter("Odkryj
Telefon Motoroli Który Pasuje " +;
"do Twojego Stylu
Życia!Odkryj Telefon "+;
"Motoroli Który","pcDescript") && UTF-8 encoded
? o.ExecuteNonQuery("update
foreigndata " +;
"set
ldescript=?pcDescript " +;
"where
ID = '_1F80YXMEE' ")
? o.naffectedrecords
Watch performance
ADO is a good solution for the Unicode problem. However,
realize that using ADO over SQL pass through has a fairly steep performance
cost. In my tests of several applications with small data retrievals and updates
the ADO throughput caused the app to loose anywhere between 30-50%. of its
performance. Data retrieval of large record sets especially can be even slower
than that, so be careful before jumping on the ADO wagon too quickly and
unconditionally. However, if you need true Unicode data access for your
application ADO is really the only way to go.
Desktop Interface
I tend to build Web applications for the most part, but as
I was working on this article I figured there must be a way to display Unicode
content in VFP as well. As mentioned earlier if you’re running in the default
locale and the Unicode data is compatible with the default locale VFP will
happily do the conversions for you and display your Unicode data in the User
Interface. Problems arise only if you need to display more than one code page at
a time. The VFP user interface basically allows you to display a single code
page at a time. This means that if you want to display output from multiple
different locales with differing character sets you’re pretty much out of luck
with the native Visual FoxPro user interface.
However, there is a workaround: You can skip using VFP
controls and use ActiveX controls instead. Figure 5 shows a very simple Visual
FoxPro form of the multi-language data I’ve been working with in this article.
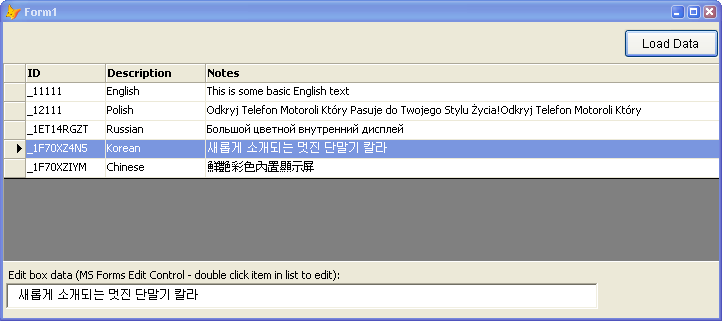
Figure 5 – Displaying Unicode in Visual FoxPro
applications requires that you use ActiveX controls. Other than the default
Locale, Visual FoxPro’s native controls cannot display Unicode. This form uses
the DataDynamics SharpGrid and the Microsoft Forms Editbox to display the
Unicode text.
The form uses the Microsoft Forms EditBox control and the
Data Dynamics SharpGrid control to display its data. I would have preferred to
use a ‘standard’ control like the ListView or even the hideous FlexGrid control
for the data, but not all ActiveX controls support Unicode character sets.
Specifically the MSCOMCTL controls (TreeView, ListView, etc.) and many other of
the old stock ActiveX controls that Microsoft shipped with Visual FoxPro are not
capable of displaying Unicode. This leaves you with finding third party controls
that do support Unicode – most of the big vendor suites (like Component Source,
Developer Express etc) support Unicode in their ActiveX controls and if you’re
going this route it might actually make sense to go with a whole suite as you
will need ALL interface controls (labels, textboxes, lists, dropdowns etc.) and
using a suite might make this process a bit more consistent.
This is obviously not an ideal solution, but at least it
can be done if necessary.
Summary
Using Unicode in Visual FoxPro is definitely not for the
faint of heart. If you are lucky and you can get away with using a single locale
specific Unicode language, Visual FoxPro’s code page translation mechanism can
get you reasonable language capabilities in your application without too much
extra work. Problems don’t arise until you have more than one language involved.
With multiple languages you have to resort to pass data
through the application using either binary or UTF-8 for strings. For data
access true Unicode support is not available in VFP’s data engine, but requires
that you use a SQL Backend like SQL Server that does support it. The only
reliable way to communicate with Unicode data from a SQL Backend is through ADO
whether you’re talking directly to ADO or you use a wrapper like the
CursorAdapter or the wwAdoSql class provided here with this article.
It’s a shame VFP doesn’t have better support for Unicode.
It seems that with a few enhancements – specifically a type that knows about
Unicode – a lot of the ugliness I’ve shown here could be removed as we would at
least be able to pass the data around the system and to the backend without
conversion. If VFP could pass Unicode data directly through ODBC we would not be
required to give up performance with ADO.
In the meantime using COM and ADO seems to be the best
solution to Unicode data. I hope that this article and the samples and wwSQL
class make this process a bit easier for you if you need to go this route.
I need to thank the following people for their significant
input:
Craig Tucker of Centiv who got me started on this
project
Aleksey Tsingauz from Microsoft for his patience
with me and his CursorAdapter help
Steven Black for some needed feedback and review
Code for this article:
http://www.west-wind.com/presentations/foxunicode/foxunicode.zip
|


